新智元报道
新智元报道
【新智元导读】MotionMAR模型,通过分层生成方式解决稀疏观测下人体运动重建难题。该模型将运动视为多尺度过程,先生成整体轮廓再细化局部动作,从而在仅用头部和双手数据时,依然能还原完整姿态,为轻量级动捕系统提供新方向。
在VR/AR场景当中,用户仅仅需要戴着头显、手握两个手柄,便能够在虚拟世界里面去完成挥手、转身以及自由移动等一系列动作。
但是设备所捕捉到的数据,实际上只有头部和双手。至于腰部究竟是怎么扭动的?腿部又是怎么迈开的?还有脚跟到底在何时落地?这些缺失的肢体动态方面的信息,完全是凭借着模型在后台进行推理来获取的。
这也就构成了稀疏观测人体运动重建面临的核心挑战:输入端只有3个追踪点,输出端却要还原22个关节的完整姿态。如果捕捉设备越少,用户的使用门槛自然也就越低;但传感器越少,则意味着模型在后台所需要去推理的信息变得更多。
面对这一挑战,厦门大学与上海科技大学联合提出了一种全新思路:不要把动作当成一串平铺的时间帧来预测,而是像人类运动的物理直觉那样,从整体的大趋势到局部的小细节,采用分层的方式来进行生成。

论文主页: http://www.lidarhumanmotion.net/motionmar/
实验室主页:https://asc.xmu.edu.cn/
论文第一作者来自厦门大学信息学院空间感知与计算实验室(ASC)2024级博士生罗裕华、2025级硕士生张俊圣,通讯作者为厦门大学沈思淇长聘副教授,并由刘梦茵、林心成、颜明、陈朱迪、温程璐教授、许岚助理教授(上海科技大学)、王程教授共同合作完成。
研究团队长期聚焦于3D人体姿态估计、快速人体运动捕捉及相关多模态数据集构建。

在MotionMAR的具体设定当中,输入的数据是头部以及左右手这三个传感器所提供的6-DoF(六自由度)刚体变换,另外再加上线速度与角速度;而最终的目标则是要输出由22个关键节点所组合而成的完整人体动作序列。
这里面真正的难点在于「一对多」的姿态歧义性。 举个例子:当你的双手位置保持不变时,你的下半身可能在静止站立,也可能正在原地踏步;当头部的运动轨迹平稳地向前行进时,躯干和腿部依然会存在着无数种不同的发力方式。
而传统的那些单尺度序列处理方法,往往会表现得顾此失彼,很难去同时兼顾到长时间的物理稳定性以及短时间内的动作细节。
针对这一点,MotionMAR所提出的思路是非常巧妙的:人体动作本来就不是单尺度的平铺信号。
它把视觉自回归生成当中那种「先去生成粗略的图像、再去补充具体细节」的内在逻辑,直接运用到了人体运动生成过程上面。
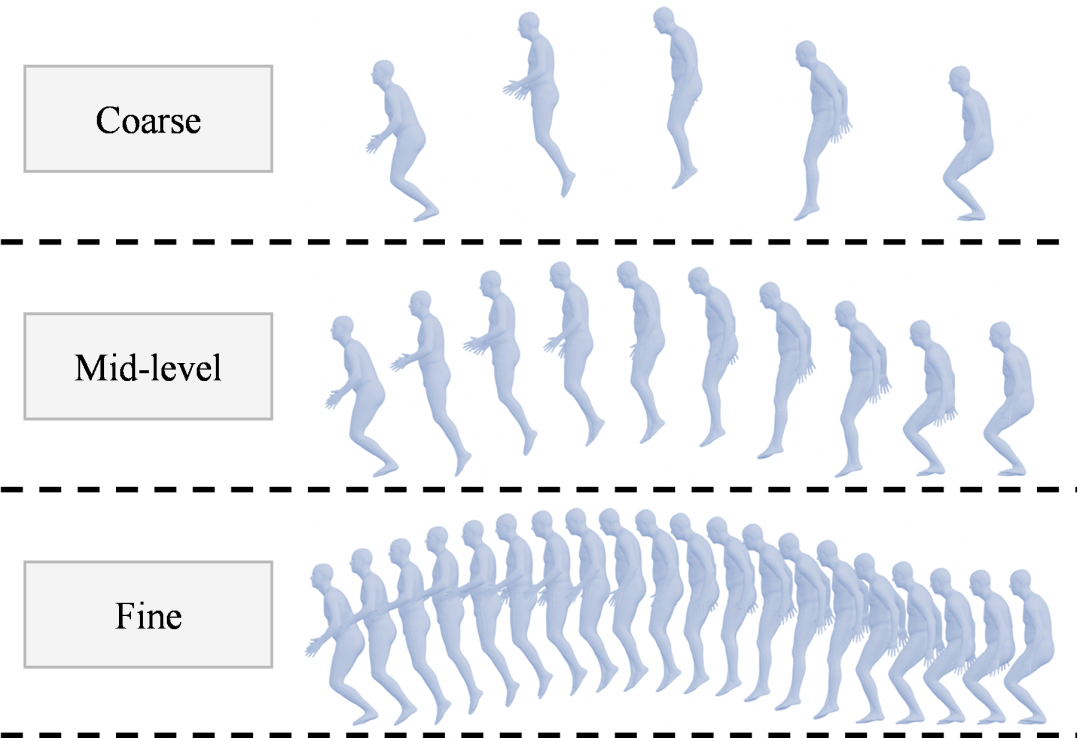
图1:MotionMAR的coarse-to-fine多尺度生成过程
MotionMAR主要是由四个核心组件共同组成:包含了时间多尺度词元量化变分自编码器(Temporal Multi-scale Tokenization VQ-VAE,TMT VQ-VAE)、尺度感知控制模块(Scale-Aware Control Module,SAC)、运动自回归网络(Motion Autoregressive Network,MAN),以及运动精炼网络(Motion Refinement Network,MRN)。
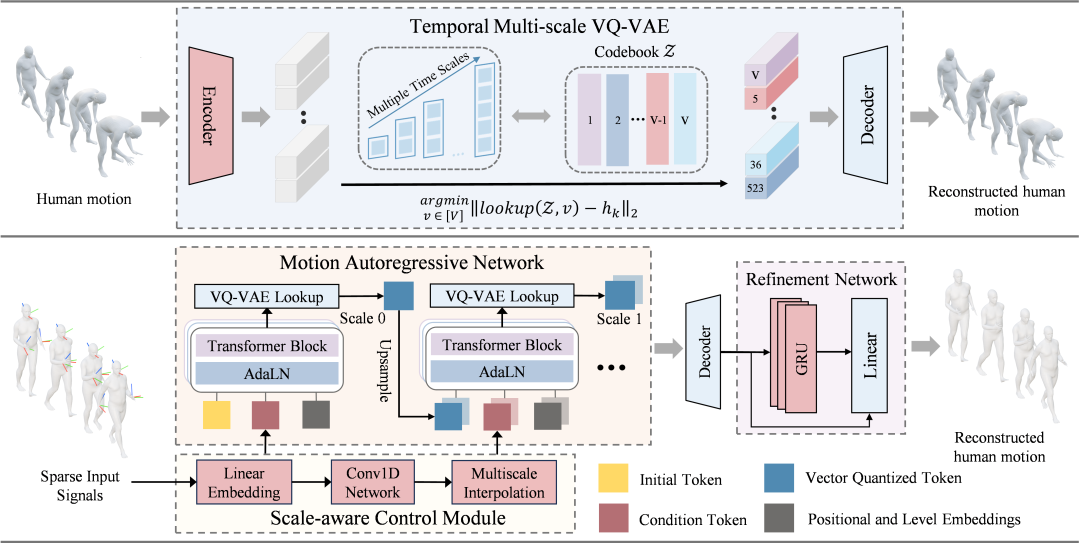
图2:MotionMAR整体框架
如图所示,TMT VQ-VAE 架构基于Transformer编码器(E)和解码器(D)构建,并与多尺度量化器协同工作。完整的人体运动数据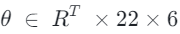 从编码器开始:它处理人体运动序列并将其压缩为连续的潜在表示
从编码器开始:它处理人体运动序列并将其压缩为连续的潜在表示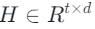 ,其中t表示时间降采样长度,d表示特征维度。经过压缩后,多尺度量化器
,其中t表示时间降采样长度,d表示特征维度。经过压缩后,多尺度量化器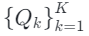 将这些连续特征映射为离散标记
将这些连续特征映射为离散标记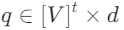 ,而后经过解码器重建完整的人体运动。TMT VQ-VAE主要功能是将连续运动序列映射到多尺度的离散潜在空间,为自回归生成提供层次先验。
,而后经过解码器重建完整的人体运动。TMT VQ-VAE主要功能是将连续运动序列映射到多尺度的离散潜在空间,为自回归生成提供层次先验。
研究人员将TMT的处理过程总结如下。
-
对于长度为 T 的输入隐变量,通过使用一个共享的码本,在K = 3个时间尺度(即 T/4、T/2、T)上对其进行逐次量化。
-
在每个尺度k下,残差特征(初始值为输入的潜在特征H)会经历以下四个步骤:首先,通过1D线性插值将残差特征降采样到分辨率t 。接下来,降采样特征和共享代码本嵌入进行L2 loss。通过余弦相似度检索降采样特征的最近码本向量。然后,将码本向量插值到原始长度T 。应用1D残差卷积块来平滑时间上的不连续性。最后,将平滑后的量化特征添加到最终重建中,并从当前残差中减去,从而得到下一层更精细尺度的输入。
SAC负责将稀疏跟踪信号投影到高维潜在空间中,随后通过一维卷积模块提取连续的局部时序特征。由于自回归网络作用于离散的多尺度token,这些连续信号需要进行时间对齐。
通过线性插值法实现这一对齐:对提取的特征进行重采样,使其精确匹配TMT VQVAE 定义的每个尺度对应的时间分辨率 。由此生成的控制特征金字塔
。由此生成的控制特征金字塔 ,使其能够同步条件信号与各尺度下的token序列长度。
,使其能够同步条件信号与各尺度下的token序列长度。
MAN可以说是整个生成过程的核心所在,并不是像以往那样逐帧地去做next-token,而是去执行next-scale的预测方式:也就是先预测粗尺度token,再预测更细尺度token;在同一层内的token是可以通过并行的方式来进行预测的,而在不同的层与层之间则是保持着一种自回归的依赖关系。
在最后阶段,MRN会在连续的姿态空间里面去进行残差修正,以此来减少量化误差和局部的抖动现象,从而让最终输出的动作能够变得更加稳定、也更加顺畅。
MotionMAR在AMASS数据集上训练和评估,模拟标准VR/XR设置,并且针对三种不同的设置进行了测试:分别是三点追踪的S1设置、加入了root joint的四追踪器S2设置,以及在更大规模数据组合情况下的S3设置。评价指标包括 MPJRE、MPJPE、MPJVE、部位级误差和Jitter。
先看最标准的三点追踪设置S1。
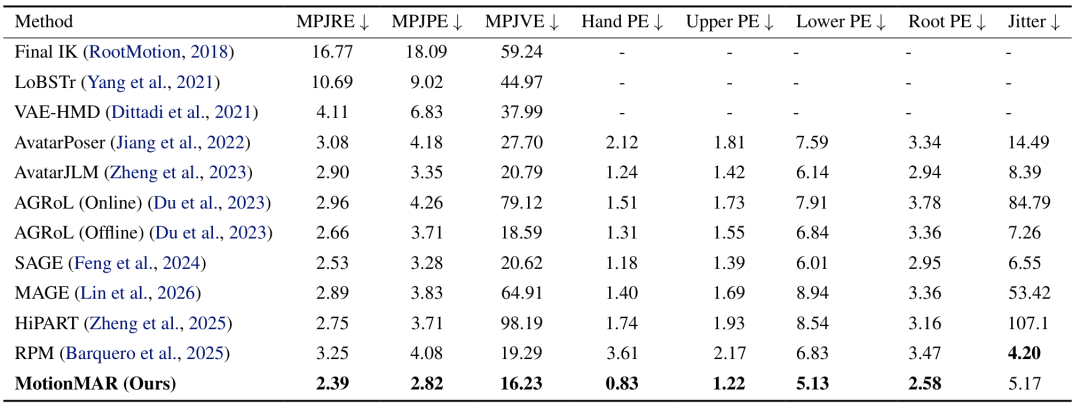
表1:S1设置下的全身运动重建结果
从表中可以看到,MotionMAR在绝大多数的重建指标上都取得了更低的误差,只有Jitter比RPM略低,但RPM在人体结构的还原以及姿态重建精度方面明显落后。
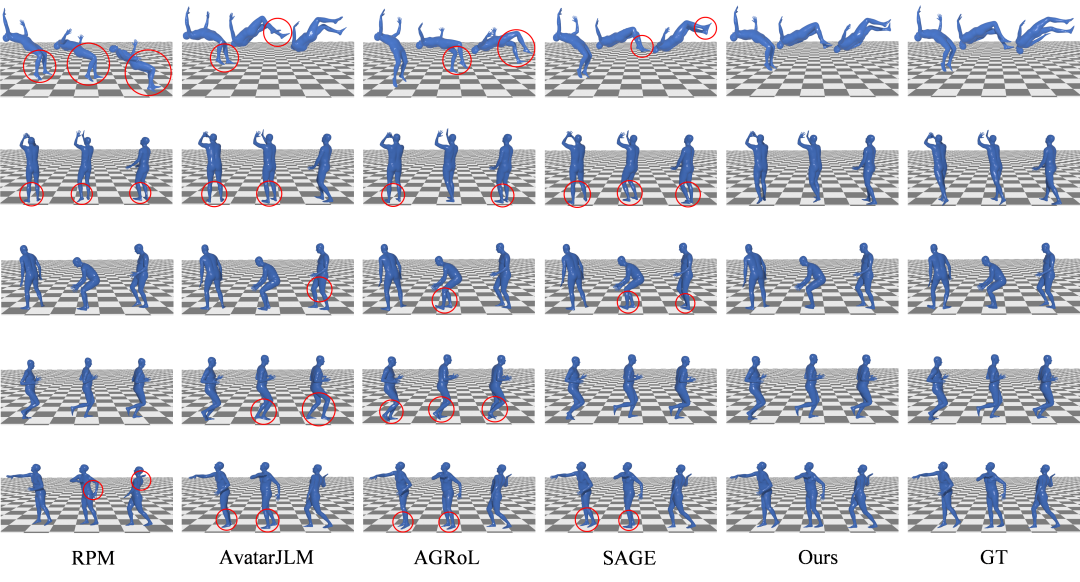
图3:MotionMAR与baseline方法的可视化对比
图中是MotionMAR在S1设置下的可视化评估。结果显示,MotionMAR在手部以及腿部等区域与Ground Truth之间的的对齐效果要表现得更好一些。
在加入了root joint之后,MotionMAR在S2设置中仍保持领先的地位。
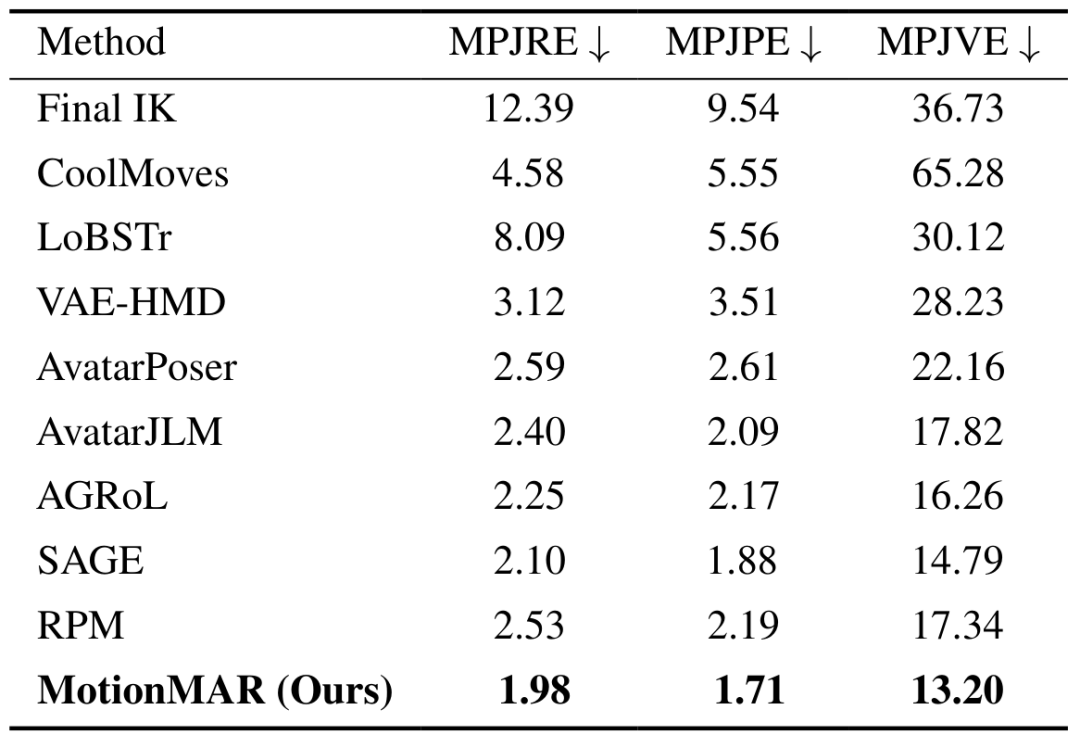
表2:S2设置下的全身运动重建结果
而更大规模数据组合下的S3设置,则是被用来测试模型的泛化能力。
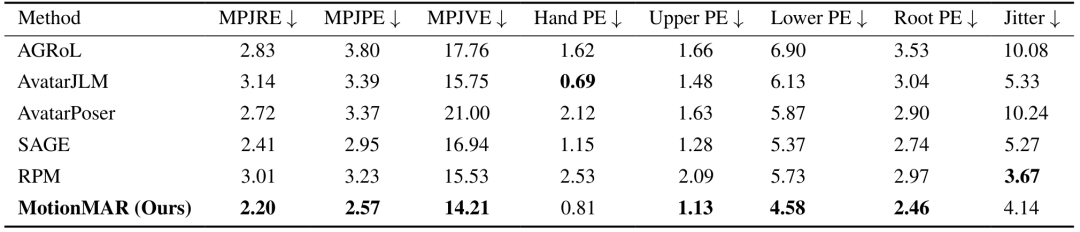
表3:S3设置下的泛化实验结果
MotionMAR在S3设置下依然保持着多数指标优势,说明了它并不只是在单一数据设置下才能够发挥作用。

为了准确地验证出每一个单独的模块有没有发挥作用,MotionMAR做了系统消融实验。

表4:MotionMAR消融实验结果
通过表格的数据我们能够发现,TMT、SAC、MRN其实各自都在解决不同问题:TMT决定了模型进行多尺度建模的能力,SAC让稀疏观测按相应的尺度进行生成,MRN则负责最后的平滑处理。
对于VR/AR应用的实际场景,模型仅仅只是做到准确还不够,还得足够快。MotionMAR的参数量为42.36M,FLOPs为1.47G,而它的推理速度则是达到了61.76 FPS,已经超过了比较常见的实时应用阈值要求了。
MotionMAR的价值并不在于简单地把视觉自回归直接搬到运动生成上面。它真正强调的是:我们在处理人体运动的时候,是应该按照时间的层级关系来进行理解的。
无论是对于VR/AR、虚拟数字人,还是动作捕捉以及人机交互这些领域,这类方法所带来的意义都是非常直接的:当硬件设备只能够去看到极其有限的几个追踪点的时候,后端的软件模型必须要做到更懂人体运动的本身规律。
同样地,这也是未来轻量级动捕系统去发展的一个非常重要的方向。

